Secondary Indexes in Distributed Databases
You partition your database by user_id for scalability. Now someone asks: “Find all users in Ahmedabad city.” Problem: Ahmedabad users are scattered across all partitions.
This is the secondary index problem in distributed systems.
The Core Problem#
Partitioned by user_id:
Server A (0-999): user_100 (amit, Ahmedabad)
Server B (1000-1999): user_1500 (vijay, Morbi)
Server C (2000-2999): user_2500 (narendra, Ahmedabad)
Query by user_id=1500? Hash to Server B. Fast.
Query by city='Ahmedabad'? Users on Server A and C. Must check all servers.
Two Approaches#
Local Indexes (Document-Partitioned)
Each server indexes its own data:
Server A: Ahmedabad → [100]
Server B: Ahmedabad → []
Server C: Ahmedabad → [2500]
Query city='Ahmedabad': Ask all 3 servers, combine results.
Pros:
- Fast writes (1 server)
- Strong consistency
Cons:
- Slow reads (scatter/gather)
Global Indexes (Term-Partitioned)
Indexes partitioned separately:
Index Server X: Ahmedabad → [100, 2500]
Query city='Ahmedabad': Hit Index Server X, then fetch from Server A and C.
Pros:
- Fast reads (targeted)
Cons:
- Slower writes (data + index, often async)
- Eventually consistent (if async)
The Fundamental Trade-off#
You can’t have all three:
- Fast writes
- Fast reads
- Strong consistency
Pick two.
Most systems pick: Fast writes + Fast reads
- Use global indexes with async updates
- Accept eventual consistency (seconds of lag)
- Because user experience > perfect consistency
Financial systems pick: Fast reads + Strong consistency
- Correctness matters more than write speed
- Accept slower writes or avoid secondary indexes
The Triangle:
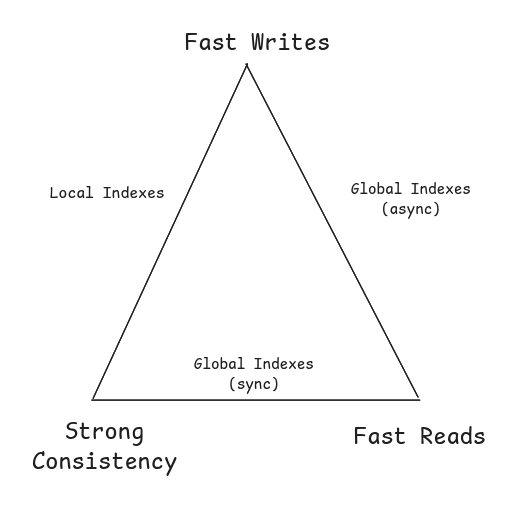
- Left edge (Fast Writes + Strong Consistency): Local indexes
- Right edge (Fast Writes + Fast Reads): Global indexes (async)
- Bottom edge (Strong Consistency + Fast Reads): Global indexes (sync)
Partitioning splits data by ONE key, but apps query by MANY. There’s no perfect solution. Understand your read/write patterns and pick the right trade-off.
Ever dealt with scatter/gather queries? How did you solve it?